

BERT词嵌入与文本相似度对比 附代码 (bert词嵌入)
本文目录导航:
BERT词嵌入与文本相似度对比(附代码)
2018年是迁徙学习模型在NLP畛域大放异彩的一年。
像Allen AI的ELMO,Open AI的GPT和Google的BERT模型,钻研人员经过对这些模型启动微调(fine-tuning)始终刷新了NLP的多项benchmarks。
在本教程中,咱们将经常使用BERT从文本数据中提取特色,即单词和句子嵌入向量。
这些单词和句子的嵌入向量可以做什么?首先,这些嵌入可用于关键字/搜查裁减,语义搜查和消息检索。
例如,假设您想将客户疑问或搜查结果与已回答的疑问或有据可查的搜查结果启动婚配,即使没无关键字或词组堆叠,这些示意方式也可以协助您准确地检索出合乎客户意图和高低文含意的结果。
其次,兴许更关键的是,这些向量被用作下游模型的高品质特色输入。
NLP模型(例如LSTM或CNN)须要以向量方式输入,这通常象征着将诸如词汇和语音局部之类的特色转换为数字示意。
过去,单词被示意为惟一索引值(one-hot编码),或许更有用地示意为神经词嵌入,其中词汇词与诸如Word2Vec或Fasttext之类的模型生成的固定长度特色嵌入相婚配。
BERT提供了优于Word2Vec之类的模型的长处,由于虽然每个单词在Word2Vec下都具备固定的示意方式,而不论该单词发生的高低文如何,但BERT都会依据周围的单词灵活地发生单词示意方式。
例如,给出两个句子:
“The man was accused of robbing a bank.” “The man went fishing by the bank of the river.”
Word2Vec将在两个句子中为单词“ bank”嵌入相反的单词,而在BERT下,每个单词中“ bank”嵌入的单词将不同。
除了捕捉诸如多义性之类的显著差异外,高低文通知的单词嵌入还捕捉其余方式的消息,这些消息可发生更准确的特色示意,从而带来更好的模型性能。
从学习的角度来看,细心审核BERT单词嵌入是学习经常使用BERT及其迁徙学习模型系列的好方法,它为咱们提供了一些通经常识和背景常识,可以更好地理解该模型的外部细节。
BERT是预训练的模型,它希冀的输入应该是有特定格局的。
接口为咱们处置好了一局部的输入规范。
(继续降级中...)
Google Assistant能很快学会正确发音姓名吗?
谷歌助手的新配置:共性化发音和默认计时器
谷歌助手正朝着更兽性化、更贴心的方向开展,近期发表了一系列严重改良。
首先,Google为纠正助手对姓名的发音提供了翻新处置打算:只有轻声说出你的名字,Google将应用其弱小的语音学习才干,让助手准确地把握你的专属发音。
旧的输入方式依然可用,但新方法无疑愈加方便和直观。
进入助手设置,找到基本消息,接着是昵称选项,但请留意,输入的文本与发音是严密相连的,例如输入Jennifer,或许会造成助手误读为Mit-hl。
这些改良也惠及你的咨询人,确保他们的名字发音愈加准确。
此外,Google借助其BERT言语了解技术,优化了计时器的高低文感知才干。
如今,只有说一句“敞开我的煮土豆计时器”,Google助手就能了解你的意图,而不是机械地口头文字婚配。
它甚至能处置复杂的指令,如设置一个比实践期间晚一小时的闹钟,或在节拍上纤细调整,如要求“设置5分钟后,立刻跳到9分钟的计时器”。
虽然以后的重点集中在计时器配置上,但Google助手的人造对话才干正逐渐裁减到更多畛域。
BERT技术的引入,无疑让谷歌助手在对话搜查和默认了解方面更上一层楼。
咱们可以等候,未来的Google助手将愈加默认,能更好地理解和满足咱们的日常需求。
总的来说,谷歌助手正以用户为核心,始终优化体验,让咱们等候更多兽性化配置的来临。
RoBERTa 和 ALBERT
BERT 模型是 2018 年提出的,并在很多人造言语处置义务有史无前例的优化。
因此 2019 年就有很多上班是围绕着 BERT 开展的,其中发生了两个 BERT 的改良版模型,RoBERTa 和 ALBERT。
RoBERTa 在更大的数据集和最优的参数中训练 BERT,使 BERT 的性能再次优化;ALBERT 关键是对 BERT 启动紧缩,经过共享一切层的参数以及 Embedding 合成缩小 BERT 的参数量。
本文关键引见 BERT 的两种改良模型 RoBERTa 和 ALBERT,关于 BERT 模型可以参考之前的文章《彻底了解 Google BERT 模型》 ,首先总体看一下 RoBERTa 和 ALBERT 的一些特点。
RoBERTa 关键实验了 BERT 中的一些训练设置 (例如 NSP Loss 能否无心义,batch 的大小等),并找出最好的设置,而后再更大的数据集上训练 BERT。
原来的 BERT 只经常使用了 16G 的数据集,而 RoBERTa 在更大的数据集上训练 BERT,经常使用了 160G 的语料:
BERT 在训练的环节中驳回了 NSP Loss,原本意图是为了让模型能够更好地捕捉到文本的语义,给定两段语句 X = [x1, x2, ..., xN] 和 Y = [y1, y2, ...., yM],BERT 中的 NSP 义务须要预测 Y 是不是 出如今 X 的前面。
然而 NSP Loss 遭到不少文章的质疑 ,例如 XLNet,RoBERTa 驳回了一个实验验证 NSP Loss 的适用性。实验中驳回了四种组合:
Segment-Pair + NSP: 这个是原来 BERT 的训练方法,经常使用 NSP Loss,输入的两段文字 X 和 Y 可以蕴含多个句子,然而 X + Y 的长度要小于 512。
Sentence-Pair + NSP: 与上一个基本相似,也经常使用 NSP Loss,然而输入的两段文字 X 和 Y 都区分是一个句子,因此一个输入蕴含的 token 通常比 Segment-Pair 少,所以要增大 batch,使总的 token 数量和 Sentence-Pair 差不多。
Full-Sentences: 不经常使用 NSP,间接从一个或许多个文档中采样多个句子,直到总长度抵达 512。
当采样到一个文档开端时,会在序列中增加一个文档分隔符 token,而后再从下一个文档采样。
Doc-Sentences: 与 Full-Sentences 相似,不经常使用 NSP,然而只能从一个文档中采样句子,所以输入的长度或许会少于 512。
Doc-Sentences 也须要灵活调整 batch 大小,使其蕴含的 token 数量和 Full-Sentences 差不多。
上图是实验结果,最上方的两行是经常使用 NSP 的,可以看到经常使用 Segment-Pair (多个句子) 要好于 Sentence-Pair (单个句子),实验结果显示经常使用单个句子会使 BERT 在下游义务的性能降低,关键要素或许是经常使用单个句子造成模型不能很好地学习常年的依赖相关。
两边两行是不经常使用 NSP Loss 的结果,可以看到两种方式都是比经常使用 NSP 成果要好的,这说明了 NSP Loss 实践上没什么作用,因此在 RoBERTa 中摈弃了 NSP Loss。
原始的 BERT 在训练之前就把数据 Mask 了,而后在整个训练环节中都是坚持数据不变的,称为 Static Mask。
即同一个句子在整个训练环节中,Mask 掉的单词都是一样的。
RoBERTa 经常使用了一种 Dynamic Mask 的战略,将整个数据集复制 10 次,而后在 10 个数据集上都 Mask 一次性,也就是每一个句子都会有 10 种 Mask 结果。
经常使用 10 个数据集训练 BERT。
下图是实验结果,可以看到经常使用 Dynamic Mask 的结果会比原来的 Static Mask 稍微好一点,所以 RoBERTa 也经常使用了 Dynamic Mask。
之前的一些关于神经网络翻译的钻研显示了经常使用一个大的 batch 并相应地增大学习率,可以减速优化并且优化性能。
RoBERTa 也对 batch 大小启动了实验,原始的 BERT 经常使用的 batch = 256,训练步数为 1M,这与 batch = 2K,训练步数 125K 的计算量是一样的,与 batch = 8K 和训练步数为 31K 也是一样的。
下图是经常使用不同 batch 的实验结果,不同 batch 学习率是不同的,可以看到经常使用 batch = 2K 时的成果最好。
BERT 的预训练模型参数量很多,训练时刻的期间也比拟久。
ALBERT 是一个对 BERT 启动紧缩后的模型,降低了 BERT 的参数量,缩小了训练所需的期间。
留意 ALBERT 只是缩小 BERT 的参数量,而不缩小其计算量。
ALBERT 能缩小训练期间,这是由于缩小了参数之后可以降低散布式训练时刻的通信量;ALBERT 不能缩小 inference 的期间,由于 inference 的时刻经过的 Transformer 计算量和 BERT 还是一样的。
上方引见 ALBERT 的一些优化方法。
这是对 Embedding 启动合成,从而缩小参数。
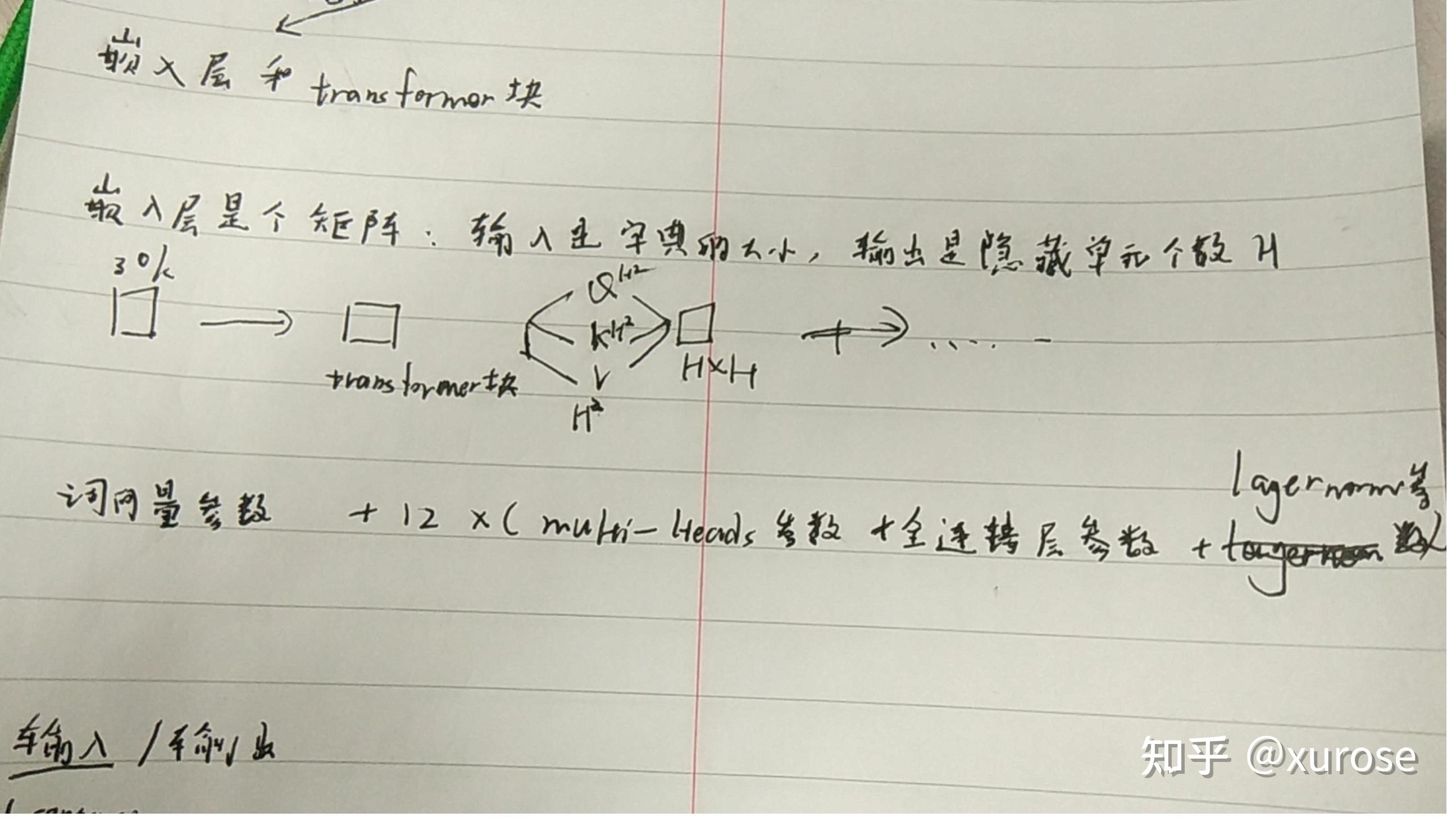
在 BERT 中,Embedding 的维度和 Transformer 暗藏层维度是一样的,都是 H。
假定词库的大小为 V,则单词的 Embedding 矩阵参数量就有 VH,假设词库很大,则参数量会很多。
因此,ALBERT 经常使用了一种基于 Factorized 的方法,不是间接把单词的 one-hot 矩阵映射到 H 维的向量,而是先映射到一个低维空间 (E 维),再映射到 H 维的空间,这个环节相似于做了一次性矩阵合成。
这个是参数共享机制,即一切 Transformer 层共享一套参数,Transformer 包括 Multi-Head Attention 的参数和 Feed-Forward 的参数。
针对不同局部的参数,ALBERT 驳回了四种方式实验。
all-shared: 共享一切的 Transformer 参数。
shared-attention: 只共享 Transformer 中 Multi-Head Attention 的参数。
shared-FFN: 只共享 Transformer 中 Feed-Forward 的参数。
not-shared: 不共享参数。
上图显示了不同共享方式模型的参数量,可以看到共享一切参数之后的模型要远远小于不共享参数的模型。
当 E = 768 时,not-shared 的参数量其实就是 BERT-base 的参数量,等于 108M,而共享一切参数后,模型的参数质变为 31M。
经过共享参数可以有效地缩小模型的参数量,另外共享参数还可以协助模型稳固网络中的参数。
作者对比了 ALBERT 和 BERT 每一层 Transformer 的输入和输入的 L2 距离,发现 ALBERT 的成果愈加平滑,如下图所示。
如 RoBERTa 结果显示的,NSP Loss 关于模型并没有什么用途,因此 ALBERT 也对 NSP 启动了一些思索。
ALBERT 以为 BERT 中经常使用的 NSP 义务过于方便了,由于 NSP 的反例是随机采样获取的,这些反例的句子通常属于不同的主题,例如前面的句子是来自体育资讯,而前面的句子来自于文娱资讯。
因此 BERT 在启动 NSP 义务时,通常是不须要真正学习句子之间的语义以及顺序的,只有要判别它们的主题类型。
ALBERT 将 NSP 交流成了 SOP (sentence order prediction),预测两个句子能否被交流了顺序。
即输入的两个句子是来自同一文档的延续句子,并随机对这两个句子的顺序启动互换,让模型预测句子能否被互换过。
这样可以让模型更好地学习句子语义消息和相互相关。
RoBERTa 更像是一个经过细心调参后获取的 BERT 模型,并且经常使用了更大的数据集启动训练。
ALBERT 对 BERT 的参数量启动了紧缩,并且能够缩小散布式训练的开支。
然而 ALBERT 并不能缩小须要的计算量,因此模型在 inference 时的速度没有优化。
RoBERTa: A Robustly Optimized BERT Pretraining Approach ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS






-
酸雨漫游者2025年11月09日
文章内容详尽,提供了关于如何优化转化率的多个方面的实用建议,...
-
GravityHacker2025年11月09日
文章内容全面,涵盖了产品优化转化的流程和思路、网站转化率优化...
-
失眠宇航员2025年11月09日
本文对Ins格调的解析十分详尽,从概述、特点到在社交媒体中的...
-
薄荷电波2025年11月09日
文章详细解析了ins格调、Ins风以及QQ音乐的社交媒体风的...
-
菠萝加密术2025年11月09日
该文章详细介绍了网站单页面的优化方法,包括关键词选取、标题设...
-
DigitalDandelion2025年11月09日
该文章详细介绍了网站单页面、SEO优化的方法和步骤,包括关键...
-
逆流时钟2025年11月09日
该店外卖品质上乘,骑手送餐速度快且态度友好,菜品新鲜美味、分...
-
信号丢失2025年11月09日
美团外卖活动券可在微信小程序支付获取,操作便捷,菜品美味且分...
-
PixelPenguin2025年11月09日
电脑软件出现问题时,首先要冷静分析原因并采取相应的修复措施,...
-
菠萝加密术2025年11月09日
电脑软件出现问题时,通过系统自带工具、sfc命令或DISM修...
文章评论