

搜查引擎上班原理 (搜索引擎调查)
本文目录导航:
搜查引擎上班原理
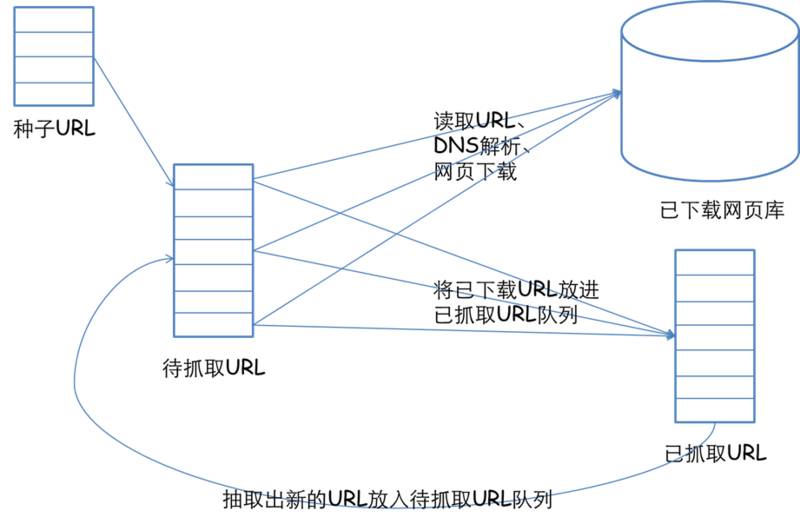
搜查引擎的上班原理总共有四步:
第一步:匍匐,搜查引擎是经过一种特定法令的软件跟踪网页的链接,从一个链接爬到另外一个链
接,所以称为匍匐。
第二步:抓取存储,搜查引擎是经过蜘蛛跟踪链接匍匐到网页,并将匍匐的数据存入原始页面数据库。
第三步:预解决,搜查引擎将蜘蛛抓取回来的页面,启动各种步骤的预解决。
第四步:排名,用户在搜查框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名环节与用户间接互动的。
不同的搜查引擎查进去的结果是依据引擎外部资料所选择的。
比如:某一种搜查引擎没有这种资料,您就查问不到结果。
定义
一个搜查引擎由搜查器、索引器、检索器和用户接四个局部组成。
检索器的配置是依据用户的查问在索引库中极速检出文档,启动文档与查问的关系度评估,对将要输入的结果启动排序,并成功某种用户关系性反应机制。
来源
一切搜查引擎的后人,是1990年由Montreal的McGillUniversity三名在校生(AlanEmtage、Peter
Deutsch、BillWheelan)发明的Archie(ArchieFAQ)。
Archie是第一个智能索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜查引擎。
因为Archie深受欢迎,受其启示,NevadaSystemComputingServices大学于1993年开发了一个Gopher(GopherFAQ)搜查工具Veronica(VeronicaFAQ)。
参考资料来源:
搜查器的配置是在互联网中遨游,发现和搜集消息。
索引器的配置是了解搜查器所搜查的消息,从中抽取出索引项,用于示意文档以及生成文档库的索引表。
用户接口的作用是输入用户查问、显示查问结果、提供用户关系性反应机制。
AlanEmtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是一个可搜查的FTP文件名列表,用户必定输入准确的文件名搜查,而后Archie会通知用户哪一个FTP地址可以下载该文件。
Jughead是起初另一个Gopher搜查工具。
网络爬虫的关键作用是什么
网络爬虫的关键作用是数据抓取和数据剖析。
网络爬虫,也被称为网页蜘蛛,是一种智能化程序,能够在互联网上搜集和失掉数据。其关键配置可以概括为两个方面:
一、数据抓取
网络爬虫能够遍历互联网上的各种网页,依照设定的规定和指标网站,智能抓取所需的数据。
这些数据可以包含网页的文本内容、图片、视频等各种格局的消息。
经过爬虫程序,可以极速地失掉少量数据,为后续的数据剖析上班提供基础。
二、数据剖析
搜集到数据后,网络爬虫可以经过一系列算法和模型对抓取到的数据启动解决和剖析。
比如,可以经过统计剖析、机器学习等技术,对网页内容、用户行为、市场趋向等启动深度开掘,协助企业做出决策,或许为学术钻研提供有价值的消息。
在网络爬虫的运行中,它可以协助企业和团体极速了解市场灵活、竞争状况,启动精准营销;在学术钻研畛域,网络爬虫可以用于搜集和剖析特定主题的数据,为学术钻研提供有力的允许。
此外,网络爬虫还可以用于网站提升、搜查引擎排名等方面的上班。
但须要留意的是,网络爬虫的经常使用必定遵守关系网站的爬虫协定以及法律法规,确保数据的非法性和正当性。
同时,为了防止对网站主机形成压力,爬虫程序须要正当设置爬取频率和数量,防止给指标网站带来不用要的累赘。
总的来说,网络爬虫在数据采集和剖析方面施展着关键作用,但其经常使用需非法合规,以确保数据的非法性和正当性。
什么是搜查引擎
搜查引擎是一个对互联网消息资源启动搜查整顿和分类,并贮存在网络数据库中供用户查问的系统,包含消息搜集、消息分类、用户查问三局部。
上班原理1.匍匐:搜查引擎是经过一种特定法令的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上匍匐一样,所以被称为“蜘蛛”也被称为“机器人”。
搜查引擎蜘蛛的匍匐是被输入了必定的规定的,它须要听从一些命令或文件的内容。
2.抓取存储:搜查引擎是经过蜘蛛跟踪链接匍匐到网页,并将匍匐的数据存入原始页面数据库。
其中的页面数据与用户阅读器失掉的HTML是齐全一样的。
搜查引擎蜘蛛在抓取页面时,也做必定的重复内容检测,一旦遇到权重很低的网站上有少量剽窃、采集或许复制的内容,很或许就不再匍匐。
3.预解决:搜查引擎将蜘蛛抓取回来的页面,启动各种步骤的预解决。





-
PhantomSnack2025年12月14日
这段文字主要介绍了搜索引擎优化(SEO)的相关知识和实践,包...
-
NeonFox_19992025年12月14日
文章内容详细介绍了SEO(搜索引擎优化)中的白帽和黑帽子技巧...
-
CosmicCroissant2025年12月14日
文章内容详细解析了关于视频中的编程内容,包括跳转指令格局、J...
-
PhantomSnack2025年12月14日
该文章详细介绍了计算机编程中的相关指令和概念,包括G31跳转...
-
番茄代码错误2025年12月14日
杨帆在SEO和网站优化方面的专业知识与实战经验令人钦佩,他的...
-
西瓜核反应堆2025年12月14日
杨帆在SEO和网站优化方面的专业知识与实战经验,为企业在网络...
-
乌龙茶涡轮2025年12月14日
该文章详细介绍了郑州网站设计公司的相关业务,包括网页设计、S...
-
宇宙快递已签收2025年12月14日
该文章详细介绍了郑州网站设计公司的团队构成及在网页设计过程中...
-
土豆超频2025年12月14日
该文章深度探讨了二次元电影营销的问题,指出当前许多影片在宣传...
-
烤面包机船长2025年12月14日
对于二次元相关影片的营销,需要更精准地把握受众共鸣点并深度理...
文章评论