

网站分析工具推荐:GSC、光年日志与SEO日志文件分析器详解

如果你想了解一个网站,就必须分析它。当然,网站分析离不开数据,可以利用GSc的大致情况。不过GSC有一定的延迟,如果延迟三到五天就可能出现问题。最好的办法就是直接查看网站的日志以及当前网站的日常分析工具,比如Lightyear、Log、Log Analyzer等,做蜘蛛分析。
Lightyear日志分析主要用于分析百度系统,日志分析器主要用于分析Google日志。
蜘蛛分析工具seologfile分析器称为SEO日志文件分析器/Screaming Frog。
这是新媒体营销的第十八手。为您推荐的是seologfileanalyzer尖叫青蛙破解版、seologfileanalyzer尖叫青蛙激活码。可以直接把百度云电缆放在这里供大家下载。
因为软件是英文的,为了以防万一你看不懂,我简单翻译了一下。除了告诉您在使用seoglogfileanalyzer/Screaming Frog 分析网站日志时应该注意什么。
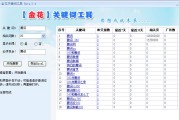
注意:站点日志通常放置在站点根目录下,通常命名为log或log。如图所示:
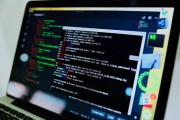
格式是. gz压缩包,可以解压,解压,用记事本打开,就可以看到代码了。如图所示:
如何分析网站日志?
1. 概述 1. uniqueurls 2. 每天的唯一 URL。活动总数 4. 活动(日常活动)5.平均6字节。平均时间(ms)(平均时间(ms)7.误差)8.暂定 10 重定向 (3xx) 重定向 (3xx) 11.clienterxx (4xx) 访客主页错误 (4xx) 12.servererror (5xx) 服务器错误 (5xx)
2. 网站(所有网站)
1.html(1)平均字节[上传+下载]观察内部大小。如果它突然太大或太小,如果它突然变成0,则当前页面可能无法捕获任何内容。 (2)如果加载时间过长且内容不多,可能是因为代码问题。 (3)Lastresponsecodes(对应结果)正常,如果4xx描述的是网页,如果是50。如果手机上有很多蜘蛛,说明手机版做得很好,或者手机版是第一选择。 2.css(1).看看吧!主要原因是扫描时间太长(2)。响应时间,如果时间过长,请检查URL是否可以打开。 (3)Spider会扫描CSS来判断网站的风格三、Ressecodes(对应结果)(1.)2xx(2.)3xx(3.)4xx(4.)5xx。
4. 用户代理(User Agent)
(1) 了解蜘蛛类型 (2)
五、目录(directory)
包理论,看看哪些目录被抓了,哪些目录被抓的多了。如果有些目录不需要重复抓取,可以直接使用robots进行拦截。根据袋子理论,袋子里的苹果数量是一定的。拿走坏苹果,你就不会得到好苹果。网站也是如此,蜘蛛会清理掉无用的目录,然后就没有精力去搜索其他目录了。例如wp-admin可以直接屏蔽。六、事件。
总计:(1)对于新站点,最好每天检查一次,了解一天中各个时间的情况。如果平时有1000个蜘蛛,而其中一个蜘蛛的数量很低,甚至是0,则说明该站点可能是K站点。
(2)如果每天的蜘蛛数量很多,而且深度足够深,说明整个网站的数据是好的。这些只是数据,具体的优化或者他们自己的优化。可以处理的是404。CSS代码问题(三)如何处理404页面: 1.直接301到首页 2.用URL重写一个新页面。




-
ZeroGravityChef2025年12月13日
龙眼与桂圆虽名称相似,但实质不同,前者为新鲜果实后者是干燥后...
-
随机散步AI2025年12月13日
对于SEO与GEO的讨论,文章深入探讨了人工智能在搜索引擎优...
-
404_Happiness2025年12月13日
随着人工智能技术的不断发展,搜索引擎优化也在经历重大变革,从...
-
PixelPenguin2025年12月13日
这篇文章深入探讨了搜索引擎优化(SEO)的关键环节,包括站内...
-
信号丢失2025年12月13日
本文详细介绍了搜索引擎优化的关键要点,包括站内链接优化、网站...
-
量子香菜2025年12月13日
该文章深入探讨了二次元一代文艺的特点和在全球文化输出领域的重...
-
啤酒与弦论2025年12月13日
本文深入探讨了二次元一代文艺的特点和影响,从媒介环境、艺术创...
-
时间褶皱2025年12月13日
该文章详细介绍了网站功能的设置和优化,包括SEO优化、重定向...
-
CosmicCroissant2025年12月13日
该设置教程详细介绍了WordPressSEO插件Rank...
-
故障烟花2025年12月13日
首衡集团积极响应数字经济发展趋势,通过电商人才培训孵化工程助...
文章评论