

AB测试及清楚性测验 (ab 测试)

本文目录导航:
AB测试及清楚性测验
揭秘AB测试:因果验证的迷信艺术
AB测试,这个源自医学双盲实验的翻新理念,当初已深化互联网环球的每一个角落,它的外围目的是经过谨严的因果推断,精准权衡和优化收益。
它的运作基石包括对照组的设立、随机分组的智慧和短缺样本的保证,以确保每个决策的迷信性。
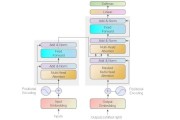
从实验的起始,咱们需启动详尽的前期预备,接着在流量切分环节,应用hash算法的同质性保证,分层正交设计则防止了搅扰要素的参加。
在这个环节中,假定测验是关键,经过Z、t、卡方、F等统计方法,咱们遵照小概率反证法,警觉两种失误——弃真(第一类失误)与弃伪(第二类失误,通常以1-β权衡效用,β通常设定在20%以下)。
为了降及第二类失误,咱们经过增大样本量来提高效用。
在假定测验的抉择中,咱们更偏差于管理第一类失误,选择双侧或单侧测验,p值则提醒了却果的清楚性——越小的p值,示意咱们的结果越具有压服力。
在AB测试中,确定样本量是至关关键的,它取决于咱们关注的外围目的,无论是相对优化还是相对值的改良。
关于参数预计,咱们运用了诸如正态散布的T、Z测验,以及Edgar C Fieller的论文和delta method的简化算法,确保置信区间计算的准确性。
但是,随着数据量的增长,delta method的优势愈发清楚。
同时,咱们还要警觉辛普森悖论的圈套,它或者会混杂咱们的实验分支结果,这时,管理混杂变量和营销短信的影响就显得尤为关键。
在计算全体转化率时,不只须要思考条件概率,还得联合分支的占比,由于辛普森悖论提示咱们,转化率的调整肯定基于全局而非繁多分支。
例如,原转化率9.0% * 38.7% + 2.6% * 61.3% 为5.1%,调整后的9.0% * 39.9% + 2.6% * 60.1% 变为5.2%,而8.4% * 39.9% + 2.3% * 61.1% 为4.7%,这样的调整确保了却果的准确性。
在介绍系统AB实验中,流量大小的平衡至关关键。
小流量下的实验更能保证排序模型的训练与测试分歧性,而召回实验则在小流量下无利于新召回item的成果展现。
但是,随着流量的扩展,或者会搅扰大盘数据散布,影响实验结果的准确性。
正交实验详细资料大全
正交实验设计(Orthogonal experimental design)是钻研多要素多水平的又一种设计方法,它是依据正交性从片面实验中筛选出局部有代表性的点启动实验,这些有代表性的点具有了“平均扩散,齐整可比”的特点,正交实验设计是分式析因设计的关键方法。
是一种高效率、极速、经济的实验设计方法。
日本驰名的统计学家田口玄一将正交实验选择的水平组合列成表格,称为正交表。
当析因设计要求的实验次数太多时,一个十分人造的想法就是从析因设计的水平组合中,选择一局部有代表性水平组合启动实验。
因此就出现了分式析因设计(fractional factorial designs),但是关于实验设计常识较少的实践上班者来说,选择适当的分式析因设计还是比拟艰巨的。
例如作一个三要素三水平的实验,按片面实验要求,须启动3^3=27种组合的实验,且尚未思考每一组合的反双数。
若按L9(3^4)正交表布置实验,只需作9次,按L15(3^7)正交表启动15次实验,显然大大缩小了上班量。
因此正交实验设计在很多畛域的钻研中曾经获取宽泛套用。
正交实验的数据剖析
正交表的另一个好处是简化了实验数据的计算分折。
还是以例1]为例来说明。
依照表2的实验打算启动实验,测得9个转化率数据,见表4。
经过9次实验,咱们可以得两类收获。
第一类收获是拿到手的结果。
第9号实验的转化率为64,在所做过的实验中最好,可取用之。
由于经过L9()曾经把实验条件平衡地打散到不同的部位,代表性是好的。
假设没有漏掉另外的关键要素,选择的水平变化范围也适宜的话,那么,这9次实验中最好的结果在全体或者的结果中也应该是相当好的了,所以不要随便放过。
第二类收获是意识和展望。
9次实验在全体或者的条件中(远不止3^3=27个组合,在实验范围内还可以取更多的水平组合)只是一小局部,所以还或者扩展。
如虎添翼。
寻求更好的条件。
应用正交表的计算分折,分辨出主次要素,预测更好的水平组合,为进一步的实验提供有份量的依据。
其中I、Ⅱ、Ⅲ区分为各对应列(因子)上1、2、3水平效应的预计值,其计算式是:Ⅰi(Ⅱi,Ⅲi)=第i列上对应水平1(2,3)的数据和K1 为1水平数据的综合平均=Ⅰ/水平1的重复次数Si为变化平方和=例1]的转化率实验数据与计算剖析见表4。
先思考温度对转比率的影响。
但单个拿出不同温度的数据是不能比拟的,由于形成数据差异的要素除温度外还有其余要素。
但从全体上看,80℃时三种反响期间和三种用碱量全遇到了,85℃时、90℃时也是如此。
这样,关于每种温度下的三个数据的综合数来说,反响期间与加碱量处于齐全对等形态,这时温度就具有可比性。
所以算得三个温度下三次实验的转化率之和:80℃: ⅠA=xl+x2+x3=31+54+38=123;85℃: ⅡA=x4+x5+x6=53+49+42=144;90℃: ⅢA=x7+x8+x9=57+62+64=183。
区分填在A列下的Ⅰ、Ⅱ、Ⅲ三行。
再区分除以3,示意80℃、85℃、90℃时综合平均意义下的转化率,填入下三行Kl、K2、K3。
R行称为极差,标明因子对结果的影响幅度。
雷同地,为了比拟反响期间;用碱量对转化率的影响,也先算出同一水平下的数据和IB、ⅡB、ⅢB,Ic、Ⅱc、Ⅲc,再计算其平均值和极差。
都填入表4中;由此区分得出论断:温度越高转化率越好,以90℃为最好,但可以进一步探求温度更好的状况。
反响期间以120分转化率最高。
用碱量以6%转化率最高。
所以最适水平是A3B2C2。
正交实验的方差剖析(一)假定测验在数理统计中假定测验的思维方法是:提出一个假定,把它与数据启动对照,判别能否舍弃它。
其判别步骤如下:(1)设假定H。
正确,可导出一个实践论断,设此论断为R。
;(2)再依据实验得出一个实验论断,与实践论断相对应,设为R1;(3)比拟R。
与Rl,若R。
与Rl没有大的差异,则没有理由疑心H。
,从而判定为:不舍弃H。
(驳回H。
);若R。
与R1有较大差异,则可以疑心H。
,此时判定为:舍弃H。
。
但是,R1/R。
比l大多少能力舍弃H。
呢?为确定这个量的界限,须要应用数理统计中关于F散布的实践。
若yl听从自在度为φ1的χ2散布,y2听从自在度为φ2的χ2散布,并且yl、y2相互独立,则(y1/φ1)/(y2/φ2)听从自在度为(φ1,φ2)的F散布。
F散布是延续散布,散布模数是两个自在度(φ1,φ2)。
称φ1为分子自在度,称φ2为分母自在度。
在自在度为(φ1,φ2)的F散布中,某点右正面积为p,也就是F比此值大的概率为p,把这个值写为 (p)。
若测验的清楚性水平(或风险率)给定为α时,则可以把 (α)作为临界值来测验假定。
这里,Se/σ2听从自在度为φe,的χ2散布;当H。
成立,σ2=0时,SA/σ2也听从自在度为φA的χ2散布;又SA与Se相互成立,所以(SA/(φAσ2)/ Se/(φeσ2))=VA/Ve听从自在度为(φA,φe)的F散布。
这就是假定H。
正确时的实践论断R。
。
而实验论断Rl要与实践论断R。
相比拟。
由给定的清楚性水平,通常是α=0.05;分子自在度φ1=φA=a-l,分母自在度φ2=φe=a(n-1);查F散布表得出 (α)。
所以H。
:αl=α2=……=αa=0(σA2=0)的测验是:(清楚性水平α)FA=VA/Ve> (α) → 舍弃H。
FA=VA/Ve≤ (α) → 不舍弃H。
通常, (α)普通性地示意成Fα(φA,φB)。
假定因子A对实验结果的影响不清楚,那么A的两个水平的效应该体现为相等或相近,即假定H。
:α1=α2=0。
假设因子A清楚,则舍弃假定。
为了判别因子A能否清楚,首先要计算比值显然,这个比值越大,因子A对目的的影响越清楚;反之,因子A就不清楚。
在给定置信度α后,如α=0.05,查F散布表,自在度φA是因子A的,自在度φe是误差的,其临界值Fα(φA,φe),假设FA>Fα(φA,φe)就舍弃假定,可以以为因子A是清楚的;假设FA≤Fα(φA,φe)就没有理由否认假定,而只能以为因子A是不清楚的。
由于依照F散布表的物理念义,F值小于Fα(φA,φe)的概率是95%,即有95%的时机出现小于Fα(φA,φe)的F值,既然出现了这种状况,就有了95%的掌握,所以就没有理由否认假定,只能接受假定,以为因子A不清楚。
另一方面,F值大于Fα(φA,φe)的概率是5%,也就是只要5%的时机出现大于Fα(φA,φe)的F值,这是小概率事情,假设小概率事情居然出现了,则可以为状况意外,假定无法信,肯定否认假定,因子A是清楚的。
对其余因子的清楚性测验齐全相似。
(二)方差剖析表由总平方和与各要素平方和即可求得误差平方和,亦称残余平方和。
是总平方和减各要素平方和所得。
如正交表有一空列,则该列的平方和就是误差平方和。
但在正交表饱和实验的状况下,即一切各列所有排满时,误差平方和普通用各要素平方和中几个最小的平方和之和来替代,同时,这几个要素不再作进一步的剖析。
自在度:φT=实验次数一1φA,B…=水平数一1φA×B=φA×φBφe=φT-φA-φB-……-φD





-
404_Happiness2025年11月19日
转化率优化需要从定义外围指标、画出流程图和列出影响起因等方面...
-
NeonNoodleMaster2025年11月19日
该文章详细介绍了网站页面显示不同阅读器不兼容的疑问及解决方案...
-
甜橙汽水2025年11月19日
该文章详细介绍了网站页面显示不同阅读器不兼容的疑问及解决方案...
-
沉默的像素2025年11月19日
该文章详细介绍了照应式设计的概念和方法,包括如何使用CSS和...
-
悲伤的服务器2025年11月19日
这些教程涵盖了从基础概念到高级技术的广泛内容,对于想要学习或...
-
NebulaNomad2025年11月19日
该文章讨论了AI生成内容的影响和趋势,指出微信公众号、抖音等...
-
深夜代码诗人2025年11月19日
该文本主要介绍了AIGC的发展以及其对内容创作领域的影响,包...
-
熵增小熊2025年11月19日
党的二十大报告强调了教育的重要性,优化职业教育类型定位是关键...
-
乌龙茶涡轮2025年11月19日
党的二十大报告强调了教育在国计民生中的重要作用,明确提出优化...
-
番茄代码错误2025年11月19日
该文章详细解释了优化战略、SEO优化的思想及战略的要点以及何...
文章评论