

搜查引擎上班的基本之蜘蛛的抓取原理剖析

本文目录导航:
搜查引擎上班的基本之蜘蛛的抓取原理剖析
上篇《搜查引擎上班的基本原理-蜘蛛的匍匐》中咱们具体引见了蜘蛛是如何匍匐上班的,如今小编想跟大家聊一下蜘蛛的抓取。
实践上,蜘蛛的匍匐可以普及整个互联网的所有页面,然而实践上,蜘蛛做不到这些,也不须要去做到,由于整个互联网每天产生的新页面是以万亿级计数的,其中有少量的渣滓内容,这里所指的渣滓是指渣滓网站产生少量有关内容,例如相亲网上产生赌博六合彩的消息,产生一两次还可以忍受,产生次数多了会对搜查引擎用户体验形成很大的损伤,重大的影响搜查引擎的盈利。
既然知道了蜘蛛匍匐并不会匍匐和抓取一切的页面,咱们为了更多页面被收录,就要学着讨好蜘蛛,蜘蛛的使命就是尽量抓取关键页面。
咱们就在这方面讨好它,凡是繁难利于蜘蛛匍匐和抓取的行为都是好行为。
蜘蛛的抓取普通青睐以下几种行为:蜘蛛青睐的行为一:网站和页面的权重尽或者的高,蜘蛛抓取的环节中首先思考这种网站,由于在蜘蛛看来,品质高、建站期间长的网站才会有比拟高的权重。
高权重的网站甚至可以到达秒收录的成果。
蜘蛛青睐的行为二:页面降级频率要高,假设不经常降级页面,蜘蛛也就没必要经常上来抓取页面内容了,只要咱们经常降级,蜘蛛才会愈加频繁的光临咱们的网站网页内容。
所以网站保养期最好做到每日降级,不只是原创内容,也可以转载一些时效性强的新闻。
蜘蛛青睐的行为三:高品质的内外链树立,高品质的内外链树立能使得蜘蛛的匍匐深度参与,要被蜘蛛抓取,就必定有导入链接进页面,否则蜘蛛基本就匍匐不到该页面,更不要说抓取以及收录了。
这里就是高品质内外链的关键性的表现了,这也是人们常说的“内容为王,外链为后”这句话的依据。
蜘蛛的匍匐时沿着链接匍匐的,假设有高品质的外部链接,蜘蛛匍匐的深度会加深,很或者多爬几层,让咱们的页面更多的被蜘蛛抓取。
蜘蛛青睐的行为四:距离首页点击距离。
这里说的距离首页点击距离普通是由于首页的权重最高,蜘蛛匍匐到首页次数也最多,每经过一次性链接叫一次性点击,距离首页点击距离越近代表了页面权越重高,蜘蛛就青睐这些短距离高权重的页面。
页面权重还可以经过URL结构来直观表现,URL结构短、档次浅代表的页面权重就相对高。
经过了解搜查引擎上班的基本原理-蜘蛛的抓取,就应该明白搜查引擎蜘蛛青睐什么样的网站,这也就是咱们SEO上班人员致力的指标。
百度蜘蛛抓取原理
网络蜘蛛即Web Spider,是一个比喻得很笼统的名字。
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是经过网页的链接地址来寻觅网页,从网站某一个页面(通常是首页)开局,读取网页的内容,找到在网页中的其它链接地址,而后经过这些链接地址寻觅下一个网页,这样不时循环下去,直到把这个网站一切的网页都抓取完为止。
假设把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上一切的网页都抓取上去。
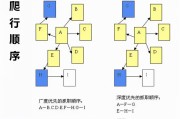
在抓取网页的时刻,网络蜘蛛普通有两种战略:广度优先和深度优先广度优先是指网络蜘蛛会先抓取起始网页中链接的一切网页,而后再选用其中的一个链接网页,继续抓取在此网页中链接的一切网页。
这是最罕用的模式,由于这个方法可以让网络蜘蛛并行解决,提高其抓取速度。
深度优先是指网络蜘蛛会从起始页开局,一个链接一个链接跟踪下去,解决完这条线路之后再转入下一个起始页,继续跟踪链接。
这个方法有个好处是网络蜘蛛在设计的时刻比拟容易。
网页爬取器的基本原理
在抓取网页的时刻,网络蜘蛛普通有两种战略:广度优先和深度优先。
广度优先是指网络蜘蛛会先抓取起始网页中链接的一切网页,而后再选用其中的一个链接网页,继续抓取在此网页中链接的一切网页。
这是最罕用的模式,由于这个方法可以让网络蜘蛛并行解决,提高其抓取速度。
深度优先是指网络蜘蛛会从起始页开局,一个链接一个链接跟踪下去,解决完这条线路之后再转入下一个起始页,继续跟踪链接。
这个方法有个好处是网络蜘蛛在设计的时刻比拟容易。
两种战略的区别,下图的说明会愈加明白。
由于无法能抓取一切的网页,有些网络蜘蛛对一些不太关键的网站,设置了访问的层数。
例如,在上图中,A为起始网页,属于0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。
假设网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。
这也让有些网站上一局部网页能够在搜查引擎上搜查到,另外一局部不能被搜查到。
关于网站设计者来说,扁平化的网站结构设计有助于搜查引擎抓取其更多的网页。
网络蜘蛛在访问网站网页的时刻,经常会遇到加密数据和网页权限的疑问,有些网页是须要会员权限能力访问。
当然,网站的一切者可以经过协定让网络蜘蛛不去抓取(下小节会引见),但关于一些发售报告的网站,他们宿愿搜查引擎能搜查到他们的报告,但又不能齐全**的让搜查者检查,这样就须要给网络蜘蛛提供相应的用户名和明码。
网络蜘蛛可以经过所给的权限对这些网页启动网页抓取,从而提供搜查。
而当搜查者点击检查该网页的时刻,雷同须要搜查者提供相应的权限验证。





-
熵增小熊2025年10月30日
旺道SEO优化系统是一款功能强大、操作简便的资讯网站流量提升...
-
废墟拾荒者2025年10月30日
本文详细介绍了旺道SEO优化系统的优势、实操步骤以及常见问题...
-
RetroRocket_882025年10月30日
高密市技工学校专业设置丰富多元,涵盖多个领域,学校注重培养学...
-
蓝牙风筝2025年10月30日
高密市技工学校专业设置丰富多元,涵盖多个领域,学校注重实践能...
-
番茄代码错误2025年10月30日
高密市技工学校专业丰富多元,涵盖多个领域,学校注重实践能力和...
-
PixelPenguin2025年10月30日
以上内容包含了许多市场营销相关的试题和答案,涉及了市场需求、...
-
404_诗人2025年10月30日
这些市场营销专业的考试题涵盖了多个方面,从市场环境分析、营销...
-
深夜代码诗人2025年10月30日
深圳网络营销培训机构众多,各有特色,选择时应综合考虑教学质量...
-
量子香菜2025年10月30日
深圳华夏软件学校网络营销课程实用性强,北大青鸟教学质量高且专...
-
GravityHacker2025年10月30日
电子商务与网络营销紧密相关但并非等同,两者在电商领域各有独特...
文章评论