

网络蜘蛛上班原理

本文目录导航:
网络蜘蛛上班原理
关于搜查引擎来说,抓取互联网的海量网页是一项艰难义务。
据统计,目前最大的搜查引擎也只能笼罩网页总量的大概百分之四十。
这关键受限于技术瓶颈,包含难以遍历一切网页和存储解决才干的限度。
假定每个网页平均大小为20KB,100亿网页将占用100×2000GB,即使能存储,下载速度也是一个应战(每秒20KB,须要340台机器延续下载一年)。
此外,数据量宏大会影响搜查效率,因此搜查引擎理论只抓取关键网页,判别关键性的依据是网页的链接深度。
搜查引擎的抓取战略分为广度优先和深度优先。
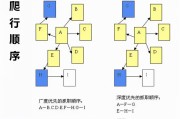
广度优先法是先抓取起始网页的一切链接,而后逐层裁减,提高抓取效率。
深度优先则是从起始页开局,一一跟踪链接,设计便捷但或者影响抓取速度。
网络蜘蛛对关键性较低的网站会设置访问层数限度,例如,假设限度为2层,深层链接或者不可被访问。
在访问网站时,网络蜘蛛会遇到权限疑问,部分网页要求用户登录。
网站一切者可以设置协定限度抓取,但有些网站宿愿被搜查而要求用户提供部分访问权限。
网络蜘蛛经过权限识别这些内容,但在用户检查时雷同须要验证。
每个网络蜘蛛都有共同的标识,如GoogleBot、BaiDuSpider等,这些消息在抓取恳求中经过User-agent字段表现。
经过日志记载,网站治理员可以追踪蜘蛛访问状况。
为了规范行为,网络蜘蛛理论会遵照协定,以定义哪些目录不能抓取。
抓取环节中,网络蜘蛛会解析网页的HTML代码,经过元标志批示抓取规定。
关于不同格局的文件,如HTML、图片等,须要不凡解决。
灵活网页的解决更为复杂,由于它们或者依赖脚本和数据库。
为了顺应变动,网络蜘蛛须要活期降级抓取内容,降级周期对搜查成果有很大影响。
最后,PR值是权衡网页关键性的目的,经过链接品质和数量计算。
外部链接的品质和数量对PR值优化有清楚影响。
经过优化网站结构和失掉高品质外部链接,可以提高网站在搜查引擎中的排名。
当“蜘蛛”程序产生时,现代意义上的搜查引擎才初露端倪。
它实践上是一种电脑“机器人”(Computer Robot),电脑“机器人”是指某个能以人类不可到达的速度不连续地口头某项义务的软件程序。
由于专门用于检索消息的“机器人”程序就象蜘蛛一样在网络间爬来爬去,反重复复,不知困倦。
所以,搜查引擎的“机器人”程序就被称为“蜘蛛”程序。
如何疏导蜘蛛爬虫系统地抓取网站
1、深度化先捜索战略从起始网页开局,选用一个URL进入,剖析这个网页中的URL,选用一个再进入。
如此深化地抓取下去,直四解决完一条路途之后再解决下一条路途。
深度优先战略设汁较为便捷。
但是用户网站提供的链接往往最具价值,PageRa址也很高,但每深化一层,网页价值和PageRank都会相应地有所降低。
这暗示了关键网页理论跑离种子较近,而适度深化抓取到的网页价值巧低。
同时,这种战略抓取深度间接影响着抓取命中率以及抓取效率,对抓取深度是该种战略的关键。
相关于其余两种战略而言。
此种战略很少被经常使用。
2、广度优先捜索战略是指在抓取环节中,在实现以后档次的捜索后,才启动下一档次的捜索。
在目前为笼罩尽或者多的网页,普通经常使用广度优先搜查方法。
也有很多钻研将广度优先搜查战略应巧于聚焦爬虫中。
其基本思维是以为与初始URL在必定链接距离内的网页具备主题关系性的概率很大。
另外一种方法是将广度优先捜索与网页过滤技术联合经常使用,先用广度优先战略抓取网页,再将其中有关的网页过滤掉。
这些方法的缺陷在于,随着抓取网页的増多,少量的有关网页将被下载并过滤,算法的效率将变低。
3、最佳优先捜索战略依照必定的网页剖析算法,预测候选URL与目的网页的相似度、或与主题的关系性,并选取评价最好的一个或几个URL启动抓取。
它只访问经过网页剖析算法预测为有用的网页。
存在的一个疑问是,在爬虫抓取门路上的很多关系网页或者被疏忽,由于最佳化先战略是一种部分最优搜查算法。
因此须要将最佳优先联合详细的运前启动改良,以跳出部分最好处。
钻研标明,这样的闭环调整可以将有关网页数量降低30% ̄90%。
蜘蛛上班原理
搜查引擎在抓取海量网页时面临诸多应战,如技术瓶颈、存储和解决疑问。
它们理论优先抓取关键网页,依据链接深度评价网页价值。
抓取战略分为广度优先和深度优先:广度优先先抓取起始网页的一切链接,提高抓取速度;深度优先则一一追踪链接,便于设计,但或者不可遍历一切层级。
并非一切网页都能被抓取,一些搜查引擎会限度访问层数,比如A为0层,B、C、D为1层,H为3层,超越设定层数的网页将不被访问。
扁平化的网站结构有助于搜查引擎抓取更多网页。
网络蜘蛛在访问时遇到加密和权限疑问,须要网站一切者经过协定控制抓取范畴。
例如,报告发售网站或者设置访问要求,准许搜查引擎索引部分消息。
每个网络蜘蛛都有共同的User-agent标识,如GoogleBot、BaiDuSpider等,网站治理员经过访问日志跟踪蜘蛛优惠。
经过,网站治理员可以定义哪些目录准许或制止抓取,如可口头文件和暂时文件目录理论被拒绝。
但是,这并不相对,不遵照协定的蜘蛛或者会访问制止的页面。
网络蜘蛛在抓取内容时,会识别HTML的META标识,判别能否抓取和跟踪链接。
关于不同格局的文件,如HTML、doc、图片等,解决模式各异,须要过滤掉无用消息,如导航链接和广告链接。
灵活网页的抓取更为复杂,特意是脚本生成的页面。
网页内容的提取是关键技术,经过插件治理服务程序解决不同类型的网页,确保抓取的准确性。
网站内容需活期降级,搜查引擎会依据降级频率调整抓取周期,关于关键网站降级频繁,关于不关键的网站则降级较慢。
了解网络蜘蛛的上班原理有助于优化网站,制造网站地图等,以顺应搜查引擎抓取规定。
节肢生物门(Arthropoda)蛛形纲(Arachnida)蜘蛛目(Araneida或Araneae)一切种的通称。
除南极洲以外,全环球散布。
从海平面散布到海拔5,000米处,均陆生。
体长1~90毫米,身材分头胸部(前体)和腹部(后体)两部分,头胸部覆以背甲和胸板。
头胸部有附肢两对,第一对为螯肢,有螯牙、螯牙尖端有毒腺启齿;直腭亚目的螯肢前后优惠,钳腭亚目者侧向静止及相向静止;第二对为须肢,在雌蛛和未成熟的雄蛛呈步足状,用以夹持食物及作觉得器官;但在雄性成蛛须肢末节膨大,变为传送精子的交接器。





-
熵增小熊2025年10月30日
旺道SEO优化系统是一款功能强大、操作简便的资讯网站流量提升...
-
废墟拾荒者2025年10月30日
本文详细介绍了旺道SEO优化系统的优势、实操步骤以及常见问题...
-
RetroRocket_882025年10月30日
高密市技工学校专业设置丰富多元,涵盖多个领域,学校注重培养学...
-
蓝牙风筝2025年10月30日
高密市技工学校专业设置丰富多元,涵盖多个领域,学校注重实践能...
-
番茄代码错误2025年10月30日
高密市技工学校专业丰富多元,涵盖多个领域,学校注重实践能力和...
-
PixelPenguin2025年10月30日
以上内容包含了许多市场营销相关的试题和答案,涉及了市场需求、...
-
404_诗人2025年10月30日
这些市场营销专业的考试题涵盖了多个方面,从市场环境分析、营销...
-
深夜代码诗人2025年10月30日
深圳网络营销培训机构众多,各有特色,选择时应综合考虑教学质量...
-
量子香菜2025年10月30日
深圳华夏软件学校网络营销课程实用性强,北大青鸟教学质量高且专...
-
GravityHacker2025年10月30日
电子商务与网络营销紧密相关但并非等同,两者在电商领域各有独特...
文章评论
该文章详细解释了网络蜘蛛的上班原理以及如何疏导其抓取网站的内容,包括广度优先和深度优两种搜索战略以及最佳化先搜素战略的优缺点等,文章内容充实且易于理解!
网络蜘蛛的上班原理十分复杂,需要遵循一定的策略和协议来抓取和解析网页,理解其工作原理有助于优化网站结构以更好地适应搜索引擎的需求和提升网站的可见性。#评论#
网络蜘蛛的上班原理十分神奇,通过广度优先和深度优抓取网站内容,理解其工作原理有助于优化网站建设并提升在搜索引擎中的表现。#评论#
网络蜘蛛的上班原理涉及到广度优先和深度优搜索战略,理解其工作原理有助于优化网站以顺应搜索引擎抓取规定。